
Attention is All You Need - Key concepts.
Transformers revolutionized deep learning by replacing recurrence and convolutions with attention. This guide explains key components, Q/K/V attention, multi-head mechanisms, and shows how these ideas power modern models like GPT, BERT, and ViT.
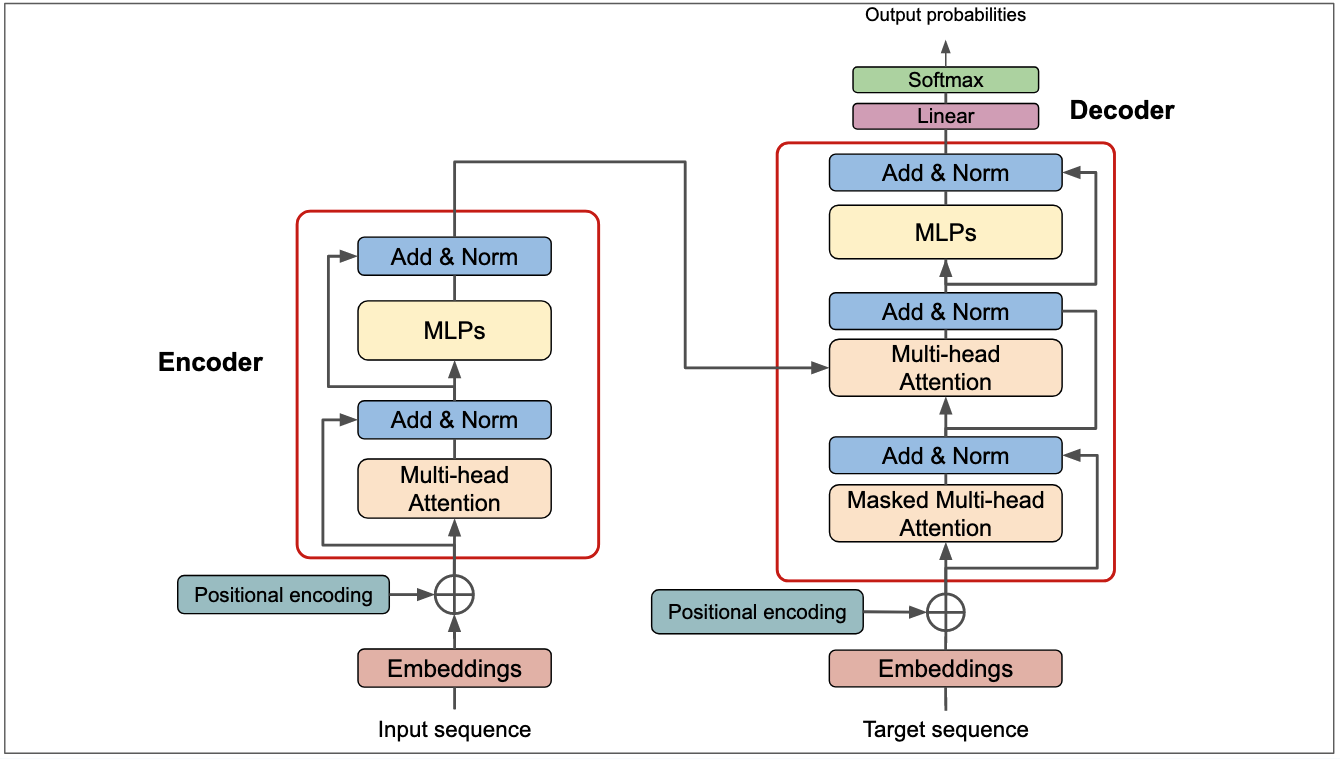
Intro
The key idea of Vaswani et al.’s “Attention Is All You Need” paper was to replace all recurrence/convolutions with multi-head attention. In practice, this means no recurrent loops: every token in a sequence is processed in parallel. This allows much faster training (on GPUs/TPUs) and yields state-of-the-art results in translation and beyond.
Before Transformers, sequence models used encoder–decoder RNNs (LSTMs/GRUs) or CNNs. Such models had two major drawbacks:
- 🚫 Sequential Processing: RNN-based Seq2Seq processed one token at a time, which hinders parallelism and slows training.
- 🔒 Information Bottleneck: Encoding a sentence into a single fixed-size vector can “forget” early words, hurting long-range dependency modeling.
Transformers overcome these by using attention layers to let each output position directly access all inputs, enabling fully parallelized training.
Computational Efficiency and Parallelism
One of the major motivations for removing recurrence was to enable parallel computation.
| Model Type | Time Complexity per Layer | Sequential Operations | Maximum Path Length |
|---|---|---|---|
| RNN | O(n·d²) | O(n) | O(n) |
| CNN | O(k·n·d²) | O(1) | O(logₖ(n)) |
| Transformer | O(n²·d) | O(1) | O(1) |
- Parallelization: Each token attends to all others simultaneously, making Transformer training highly parallelizable on GPUs/TPUs.
- Contextual Depth: Unlike RNNs, which propagate information step-by-step, Transformers access global context in a single step.
Core Idea: Attention Mechanisms
An attention mechanism lets the model “focus” on the most relevant parts of the input when producing each output. Given Queries (Q), Keys (K) and Values (V), the scaled dot-product attention is:
scores = (Q @ K.transpose(-2,-1)) / sqrt(d_k) # pairwise similarity
weights = softmax(scores, dim=-1) # normalized weights
output = weights @ V # weighted sum of values
Each input token embedding is linearly projected into three vectors: Query, Key, and Value:
🔹 Query (Q): What we are currently looking up.
🔹 Key (K): How each token is described.
🔹 Value (V): The content of each token.
Multi-Head Attention
The Transformer uses multiple heads in parallel to capture different relationships in the data. Concretely, the model splits the embedding dimension across multiple heads, concatenates their outputs, and projects back to the original embedding dimension.
Code-Level Breakdown
Multi-head attention allows the model to jointly attend to information from different representation subspaces.
Example:
def multi_head_attention(Q, K, V, n_heads):
d_model = Q.size(-1)
d_k = d_model // n_heads
Q = Q.view(batch_size, n_heads, seq_len, d_k)
K = K.view(batch_size, n_heads, seq_len, d_k)
V = V.view(batch_size, n_heads, seq_len, d_k)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
weights = torch.softmax(scores, dim=-1)
output = torch.matmul(weights, V)
# Concatenate and project
output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return output
Each head captures different linguistic or semantic relationships:
- One head may focus on syntax (e.g., subject–verb agreement)
- Another on coreference or long-range dependencies
Transformer Encoder & Decoder
Encoder Layer
Each encoder layer has a multi-head self-attention sublayer and a position-wise feed-forward sublayer, both with residual connections and layer normalization.
Decoder Layer
The decoder layer has masked self-attention, encoder-decoder attention, and feed-forward sublayers, each with residual connections and normalization.
Positional Encoding
Since Transformers have no notion of sequence order, we add sinusoidal positional encodings:
def positional_encoding(t, i, d):
if i % 2 == 0:
return math.sin(t / (10000 ** (2 * i / d)))
else:
return math.cos(t / (10000 ** (2 * i / d)))
This encoding is added to the input embeddings to preserve order information.
Modern Alternatives
Original Transformers use sinusoidal positional encodings, but newer architectures explore:
- Learned Positional Embeddings: Trainable parameters per position.
- Rotary Position Embeddings (RoPE): Used in GPT-NeoX and LLaMA.
- ALiBi (Attention with Linear Biases): Enables extrapolation to longer sequences.
These enhancements improve long-context modeling and extrapolation beyond training sequence lengths.
Putting It All Together
Example PyTorch implementation of a single Transformer encoder layer:
import torch
import torch.nn as nn
import math
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model=512, nhead=8, d_ff=2048):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead)
self.ff = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model)
)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
def forward(self, x, src_mask=None):
attn_output, _ = self.self_attn(x, x, x, attn_mask=src_mask)
x = self.norm1(x + attn_output) # Residual + Norm
ff_output = self.ff(x)
x = self.norm2(x + ff_output) # Residual + Norm
return x
Transformer Variants and Scaling Insights
Since 2017, Transformers evolved into powerful architectures:
- BERT (2018): Bidirectional encoder-only Transformer for understanding tasks.
- GPT (2018–2025): Decoder-only Transformer for autoregressive generation.
- T5 (2019): Text-to-text model using encoder–decoder.
- ViT (2020): Vision Transformer applied to image patches.
Scaling laws (Kaplan et al., 2020) show performance improves predictably with:
- Model size (parameters)
- Dataset size
- Compute budget
Practical Insights for Implementation
-
Masking:
- Use causal masks in decoders to prevent future token access.
- Use padding masks to ignore padded tokens in batches.
-
Initialization:
- Layer normalization before sublayers (
Pre-LN) improves training stability in deep networks.
- Layer normalization before sublayers (
-
Training Efficiency:
- Use mixed precision (FP16/BF16) to speed up training.
- Gradient checkpointing reduces memory usage for large models.
-
Optimization:
- AdamW optimizer with learning rate warmup and cosine decay.
- Typical warmup: 10k–20k steps.
-
Batching:
- Dynamic batching by sequence length improves GPU utilization.
Real-World Applications
Transformers power almost all modern generative models:
- ChatGPT / Claude / Gemini: Decoder-only Transformers.
- BERT / RoBERTa: Encoder-only models for classification, NER, QA.
- Whisper: Speech-to-text Transformer.
- ViT / CLIP: Image and multimodal Transformers.
Understanding self-attention helps in adapting these models to new domains (e.g., code, audio, video).
Visualizing Attention
Attention matrices can be visualized to interpret model behavior:
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(weights[0].detach().cpu(), cmap="viridis")
plt.title("Attention Weights for Head 1")
plt.show()
These plots often reveal:
- Which words attend to others.
- How long-range dependencies are modeled.
Conclusion
The Transformer’s use of attention and parallel processing revolutionized NLP. Vaswani et al.’s paper is foundational in modern AI, forming the architecture for LLMs like GPT and BERT. Understanding each component: Q/K/V vectors, multi-head attention, positional encodings, and encoder/decoder layers helps to build state-of-the-art models.


